Hands-On Speech Recognition Engine with Keras and Python

Have you ever wondered how speech recognition algorithms work? These algorithms are increasingly popular, especially in personal assistants, such as Amazon, Siri and Google Assistent.
Speech recognition is the ability of a machine or program to identify words and phrases in spoken language and convert them to a machine-readable format. Usually, simple implementations of these algorithms has a limited vocabulary, and it may only identify words/phrases if they are spoken very clearly. However, more sophisticated algorithms such as Cloud Speech-to-Text from Google and Amazon Transcribe, have a wide vocabulary and embrace of regionalism, noise and slang.
In this context, today I will report how to build a speech recognition model to recognize short commands. Best of all, developing and including speech recognition in a Python project using Keras is really simple. In this article, I will demonstrate:
- How speech to text works
- How to process audio to be transcribed
- A deep learning model using Keras to solve this challenge
- One way to evaluate this model
- A script to integrate the predictive model in your project
Overview
Speech is simply a series of sound waves created by our vocal chords when they cause air to vibrate around them. These soundwaves are recorded by a microphone, and then converted into an electrical signal. The signal is then processed using advanced signal processing technologies, isolating syllables and words. Over time, the computer can learn to understand speech from experience, thanks to incredible recent advances in deep learning.
Speech recognition works using algorithms through acoustic and language modeling. Acoustic modeling represents the relationship between linguistic units of speech and audio signals; language modeling matches sounds with word sequences to help distinguish between words that sound similar. Often, deep learning models based on recurrent layers are used to recognize temporal patterns in speech to improve accuracy within the system. However, other approaches such as Hidden Markov model (the first speech recognition algorithms were made using this approach) can also be used. In this article, I will talk only about acoustic model.
Signal Processing
There are many ways to transform an audio waves into elements that an algorithm can process, one of these ways, and the one that we will use in this tutorial, is to record the height of the audio waves in equally spaced points:
We are reading thousands of times per second and recording a number that represents the height of the sound wave at that moment. Basically, it is an uncompressed .wav audio file. The “CD Quality” audio is sampled at 44.1 kHz (44,100 readings per second). But for speech recognition, a sampling rate of 16khz (16,000 samples per second) is sufficient to cover the frequency range of human speech.
In this way an audio is represented through a number vector, in which each number represents the amplitude of the sound wave in intervals of 1/16000 of a second. This process is similar to what happens with image pre-processing, as can be seen in the example below:
Thanks to Nyquist’s theorem (1933 — Vladimir Kotelnikov), we know that we can use mathematics to perfectly reconstruct the original sound wave from spaced samples — as long as we sample at least twice as fast as the highest frequency we want to record.
Hands-On
In order to perform this task, I used an Anaconda environment (Python 3.7) with the following Python libraries:
- ipython (v 7.10.2)
- keras (v 2.2.4)
- librosa (v 0.7.2)
- scipy (v 1.1.0)
- sklearn (v 0.20.1)
- sounddevice (v 0.3.14)
- tensorflow (v 1.13.1)
- tensorflow-gpu (v 1.13.1)
- numpy (v 1.17.2)
The experiments were performed on a machine with the following hardware: Ryzen 5 3400g (4 CPU), 16 GB memory, NVIDIA GeForce GTX 1060, Ubuntu 18.04)
1. Dataset
We used in our experiments the Speech Commands Datasets provided by TensorFlow. It includes 65,000 one-second long utterances of 30 short words, by thousands of different people. We’ll build a speech recognition system that understands simple spoken commands. You can download the dataset from here.
2. Preprocessing the audio waves
In the used dataset, the duration of a few recordings is less than 1 second and the sampling rate is too high. So, let us read the audio waves and use the below-preprocessing steps to deal with this. Here are the two steps we’ll follow:
- Resampling
- Removing shorter commands of less than 1 second
Let us define these pre-processing steps in the below code snippet:
for label in labels:
waves = [f for f in os.listdir(train_audio_path + '/'+ label) if f.endswith('.wav')]
for wav in waves:
samples, sample_rate = librosa.load(train_audio_path + '/' + label + '/' + wav, sr = 16000)
samples = librosa.resample(samples, sample_rate, 8000)
if(len(samples)== 8000) :
all_wave.append(samples)
all_label.append(label)From the above, we can understand that the sampling rate of the signal is 16000 hz. Let us resample it to 8000 hz since most of the speech related frequencies are present in 8000 hz.
The second step is treat our labels, here we convert the output labels to integer encoded and convert the integer encoded labels to a one-hot vector since it is a multi-target problem:
label_enconder = LabelEncoder()
y = label_enconder.fit_transform(all_label)
classes = list(label_enconder.classes_)
y = np_utils.to_categorical(y, num_classes=len(labels))The last step of pre-processing step is reshape the 2D array to 3D since the input to the conv1d must be a 3D array:
all_wave = np.array(all_wave).reshape(-1,8000,1)3. Create train and validation set
In order to perform our deep learning model, we will need generate two sets (train and validate). For this experiment, I train the model with 80% of the data and validate on the remaining 20%:
x_train, x_valid, y_train, y_valid = train_test_split(np.array(all_wave),np.array(y),stratify=y,test_size=0.2,random_state=777,shuffle=True)4. Model Architecture
I used Conv1d and GRU layers to model the network that is used for speech recognition. Conv1d is a convolutional neural network which performs the convolution along only one dimension and GRU (Gated Recurrent Unit) aims to solve the vanishing gradient problem which comes with a standard recurrent neural network. GRU can also be considered as a variation on the LSTM because both are designed similarly and, in some cases, produce equally excellent results.
This proposed model was based on DeepSpeech2 and Wav2letter++ algoritms, two well known speech recognition approaches. The code below illustrate the proposed model using Keras:
inputs = Input(shape=(8000,1))
x = BatchNormalization(axis=-1, momentum=0.99, epsilon=1e-3, center=True, scale=True)(inputs)#First Conv1D layer
x = Conv1D(8,13, padding='valid', activation='relu', strides=1)(x)
x = MaxPooling1D(3)(x)
x = Dropout(0.3)(x)#Second Conv1D layer
x = Conv1D(16, 11, padding='valid', activation='relu', strides=1)(x)
x = MaxPooling1D(3)(x)
x = Dropout(0.3)(x)#Third Conv1D layer
x = Conv1D(32, 9, padding='valid', activation='relu', strides=1)(x)
x = MaxPooling1D(3)(x)
x = Dropout(0.3)(x)x = BatchNormalization(axis=-1, momentum=0.99, epsilon=1e-3, center=True, scale=True)(x)x = Bidirectional(CuDNNGRU(128, return_sequences=True), merge_mode='sum')(x)
x = Bidirectional(CuDNNGRU(128, return_sequences=True), merge_mode='sum')(x)
x = Bidirectional(CuDNNGRU(128, return_sequences=False), merge_mode='sum')(x)x = BatchNormalization(axis=-1, momentum=0.99, epsilon=1e-3, center=True, scale=True)(x)#Flatten layer
# x = Flatten()(x)#Dense Layer 1
x = Dense(256, activation='relu')(x)
outputs = Dense(len(labels), activation="softmax")(x)model = Model(inputs, outputs)
model.summary()

Note: If you will use only CPU to train this model, please replace the CuDNNGRU layer with GRU.
The next step is to define the loss function to be categorical cross-entropy since it is a multi-classification problem:
model.compile(loss='categorical_crossentropy', optimizer='nadam', metrics=['accuracy'])Early stopping and model checkpoints are the callbacks to stop training the neural network at the right time and to save the best model after every epoch:
early_stop = EarlyStopping(monitor='val_loss', mode='min', verbose=1, patience=15, min_delta=0.0001)
checkpoint = ModelCheckpoint('speech2text_model.hdf5', monitor='val_acc', verbose=1, save_best_only=True, mode='max')Let us train the model on a batch size of 32 and evaluate the performance on the holdout set:
hist = model.fit(
x=x_train,
y=y_train,
epochs=100,
callbacks=[early_stop, checkpoint],
batch_size=32,
validation_data=(x_valid,y_valid)
)And the output of this command is:
5. Diagnostic plot
I’m going to lean on visualization again to understand the performance of the model over a period of time:
pyplot.plot(hist.history['loss'], label='train')
pyplot.plot(hist.history['val_loss'], label='test')
pyplot.show()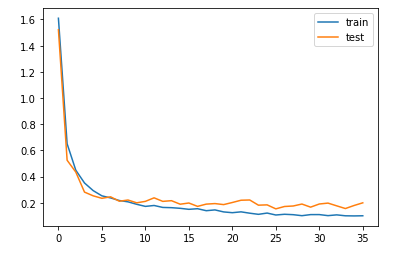
6. It’s time to predict
In this step, we will load the best weights and define the function that recognizes the audio and converts it to text:
model = load_model("speech2text_model.hdf5")def s2t_predict(audio, shape_num=8000):
prob = model.predict(audio.reshape(1,shape_num,1))
index = np.argmax(prob[0])
return classes[index]
Prediction time! Make predictions on the validation data:
index = random.randint(0,len(x_valid) - 1)
samples = x_valid[index].ravel()print("Audio:", classes[np.argmax(y_valid[index])])
print("Predicted Text:", s2t_predict(samples))ipd.Audio(samples, rate=8000)
Here is a script that prompts a user to record voice commands. Record your own voice commands and test it on the model:
samplerate = 16000# the value below must be in seconds
duration = 1filename = 'recorded_audio.wav'
print("start")mydata = sd.rec(int(samplerate * duration), samplerate=samplerate,
channels=1, blocking=True)print("end")sd.wait()
sf.write(filename, mydata, samplerate)
Finally, we create a script to read the saved voice command and convert it to text:
audio, audio_rate = librosa.load('recorded_audio.wav', sr=16000)
audio_sample = librosa.resample(audio, audio_rate, 4351)ipd.Audio(audio_sample,rate=8000)print("Predicted Text:", s2t_predict(audio_sample))
Final Remark
Speech recognition technology is already a part of our everyday lives, but for now is still limited to relatively simple commands. As the technology advances, researchers will be able to create more intelligent systems that understand conversational speech. In this article, I reported a speech-to-text algorithm based on two well-known approaches to recognize short commands using Python and Keras.
The talk presentation and the code is available in GitHub.
Processing, interpreting and understanding an audio wave is the key to many powerful new technologies and methods of communication. Given current trends, speech recognition technology will be a fast-growing (and world-changing) subset of signal processing for years to come.
In the next steps, I will work with the language model to correct the output of this approach. I hope this article has been useful for you and until next time.
References
[1] Learn how to Build your own Speech-to-Text Model (using Python). Aravind Pai. 2019
[2] Deep Speech 2: End-to-End Speech Recognition in English and Mandarin. Dario Amodei et al. 2015
